在处理大语言模型任务中,您可以根据实际业务部署情况,选择在不同环境(例如GPU云服务器环境或Docker环境)下安装推理引擎DeepGPU-LLM,然后通过使用DeepGPU-LLM工具实现大语言模型(例如Llama模型、ChatGLM模型、百川Baichuan模型或通义千问Qwen模型)在GPU上的高性能推理优化功能。
安装DeepGPU-LLM
根据您的业务场景不同,支持在GPU云服务器环境或者Docker环境下安装DeepGPU-LLM。
在GPU云服务器环境下安装DeepGPU-LLM
LLM模型的特性一般适用于GPU计算型实例,本文以GPU计算型实例规格gn7i为例,更多信息,请参见GPU计算型。
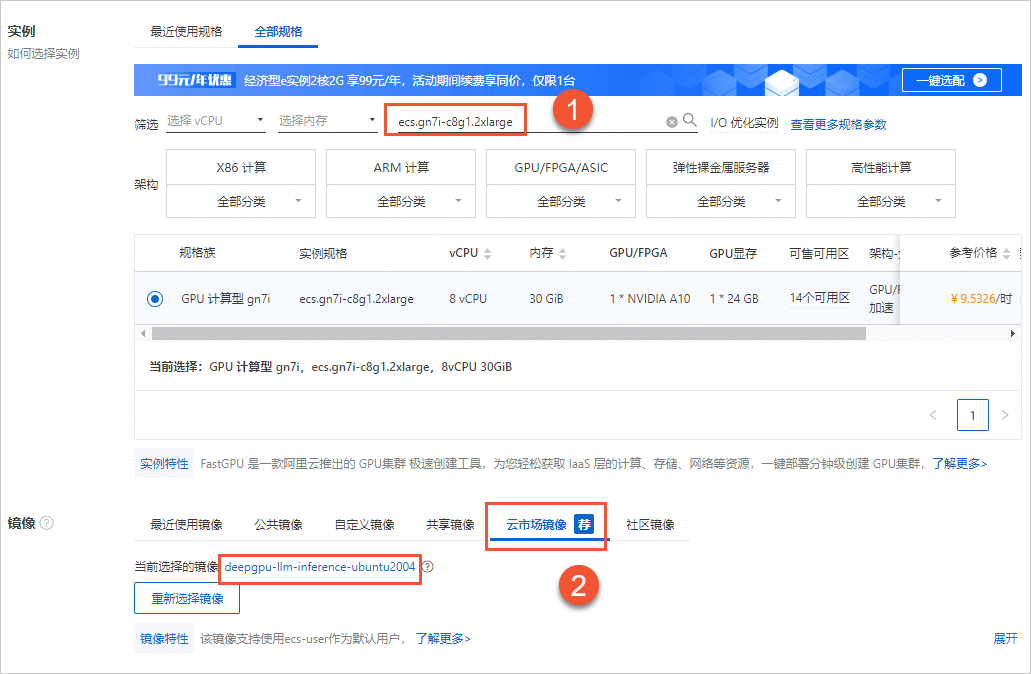
创建GPU实例。
前往实例创建页。
选择自定义购买页签。
按需选择付费类型、地域、实例规格、镜像等配置。
需要注意的参数项设置如下图所示,其他配置项参数的详细说明,请参见配置项说明。
远程连接已创建的GPU实例。
具体操作,请参见通过密码或密钥认证登录Linux实例。
执行以下命令,安装DeepGPU-LLM。
根据所需DeepGPU-LLM版本和环境依赖PyTorch版本、CUDA版本,选择合适的DeepGPU-LLM安装包。其中:
如果环境依赖为PyTorch 2.0+CUDA 11.8或PyTorch 2.0+CUDA 11.7,则选择deepgpu_llm-x.x.x+pt2.0cu117-py3-none-any.whl安装包(默认环境);如果选择其他安装包,则需要升级或降级当前的依赖软件。
x.x.x应替换为您实际的DeepGPU-LLM版本号。如何获取最新DeepGPU-LLM版本号,请参见DeepGPU-LLM加速安装包。
# for PyTorch 1.13
pip3 install deepgpu_llm-x.x.x+pt1.13cu117-py3-none-any.whl
# for PyTorch 2.0
pip3 install deepgpu_llm-x.x.x+pt2.0cu117-py3-none-any.whl
# for PyTorch 2.1
pip3 install deepgpu_llm-x.x.x+pt2.1cu121-py3-none-any.whl
(条件必选)如果使用Qwen模型,执行以下命令,安装依赖库。
pip install einops transformers_stream_generator tiktoken
在Docker环境下安装DeepGPU-LLM
准备Docker环境。
执行以下命令,安装或升级docker-ce。
apt update
apt remove docker docker-engine docker-ce docker.io containerd runc
apt install apt-transport-https ca-certificates curl gnupg-agent software-properties-common
curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
apt-key fingerprint 0EBFCD88
add-apt-repository "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
apt update
apt install docker-ce
docker -v
执行以下命令,安装nvidia-container-toolkit。
$ curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list \
&& \
sudo apt-get update
$ apt-get install -y nvidia-container-toolkit
$ nvidia-ctk runtime configure --runtime=docker
$ systemctl restart docker
如需了解更多信息,请参见Installing the NVIDIA Container Toolkit。
执行以下命令,在Docker环境中拉取并启用Docker镜像。
# torch 2.0, cuda 11.7
docker pull pytorch/pytorch:2.0.1-cuda11.7-cudnn8-devel
docker run -ti --gpus all --name="deepgpu_llm" --network=host \
-v /root/workspace:/root/workspace \
--shm-size 5g pytorch/pytorch:2.0.1-cuda11.7-cudnn8-devel
# torch 2.1, cuda 12.1
docker pull pytorch/pytorch:2.1.0-cuda12.1-cudnn8-devel
docker run -ti --gpus all --name="deepgpu_llm" --network=host \
-v /root/workspace:/root/workspace \
--shm-size 5g pytorch/pytorch:2.1.0-cuda12.1-cudnn8-devel
主要参数说明如下:
参数项 | 说明 |
--shm-size
| 指定容器的共享内存大小,其大小会影响Triton服务器部署。 例如:--shm-size 5g表示将共享内存大小设置为5 GB。您可以根据需要调整此值,以满足您的模型推理所需的内存需求。 |
-v /root/workspace:/root/workspace
| 将主机目录映射到Docker中的相应目录,使得主机和Docker之间可以共享文件,请根据自己实际环境情况进行映射。 |
pytorch/pytorch:2.0.1-cuda11.7-cudnn8-devel
| PyTorch的Docker映像标签。 |
pytorch/pytorch:2.1.0-cuda12.1-cudnn8-devel
|
执行以下命令,安装依赖库。
apt update
apt install openmpi-bin libopenmpi-dev curl
上述命令安装的openmpi-bin提供了OpenMPI、libopenmpi-dev软件包以及curl软件包。
安装DeepGPU-LLM。
根据所需的DeepGPU-LLM版本和依赖PyTorch版本,通过pip3 install命令安装DeepGPU-LLM。其中,x.x.x应替换为您实际的DeepGPU-LLM版本号。如何获取最新DeepGPU-LLM版本号,请参见DeepGPU-LLM加速安装包。
# for PyTorch 1.13
pip3 install deepgpu_llm==x.x.x+pt1.13cu117 \
-f https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/aiacc-inference-llm/deepgpu_llm.html
# for PyTorch 2.0
pip3 install deepgpu_llm==x.x.x+pt2.0cu117 \
-f https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/aiacc-inference-llm/deepgpu_llm.html
# for PyTorch 2.1
pip3 install deepgpu_llm==x.x.x+pt2.1cu121 \
-f https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/aiacc-inference-llm/deepgpu_llm.html
(条件必选)如果使用Qwen模型,执行以下命令,安装依赖库。
pip install einops transformers_stream_generator tiktoken
使用DeepGPU-LLM
DeepGPU-LLM安装成功后,您可以参考不同模型的推理示例代码编写自己的推理代码,也可以使用软件包自带的代码进行推理优化服务。无论DeepGPU-LLM安装在GPU云服务器环境中还是Docker环境中,其使用方法一样,本操作以使用安装在GPU云服务器环境中的DeepGPU-LLM为例。
步骤一:准备模型
下载模型前,您已成功登录GPU实例。更多信息,请参见连接方式概述。
huggingface格式的模型
执行以下命令,下载huggingface格式的开源模型。
模型名称 | 下载命令 |
Llama | git-lfs clone https://huggingface.co/meta-llama/Llama-2-7b
|
ChatGLM | git-lfs clone https://huggingface.co/THUDM/chatglm2-6b
|
Baichuan | git-lfs clone https://huggingface.co/baichuan-inc/Baichuan-13B-Chat
|
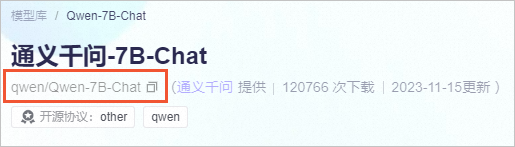
通义千问Qwen | git-lfs clone https://huggingface.co/Qwen/Qwen-7B-Chat
|
执行以下命令,进行开源模型格式转换。
使用DeepGPU_LLM前,您需要先将huggingface格式的开源模型转换为DeepGPU_LLM支持的格式,然后才能使用DeepGPU_LLM进行模型的推理优化服务。以下为四类开源模型转换方法:
在使用模型转换脚本前,请先了解各命令参数含义:
参数名 | 说明 |
huggingface_xxx_convert
| xxx可以替换为具体的模型名称,本参数表示各模型的转换脚本。
|
in_file
| 待转换的原始模型所在路径。 |
saved_dir
| 格式转换后的模型所存放的路径。 |
infer_gpu_num
| 模型切分份数或推理使用的GPU卡数。 |
weight_data_type
| 模型使用的精度,例如fp16。 |
model_name
| 模型自定义的名称,可任意填写。 |
说明 脚本运行完成后,会在/path/to/llama-7b-hf-converted/${ infer_gpu_num }-gpu/下生成格式转换后的模型。例如infer_gpu_num=1,则格式转换后的最终路径为/path/to/llama-7b-hf-converted/1-gpu/。
Llama 1/2系列模型
通过huggingface_llama_convert脚本将huggingface格式的Llama 1/2系列模型转换为DeepGPU_LLM支持的格式,具体方法如下所示:
# llama 7b weight convert
huggingface_llama_convert \
-in_file /path/to/llama-7b-hf/ \
-saved_dir /path/to/llama-7b-hf-converted/ \
-infer_gpu_num 1 \
-weight_data_type fp16 \
-model_name llama-7b
Chatglm-6b模型
通过huggingface_glm_convert脚本将huggingface格式的Chatglm-6b模型转换为DeepGPU_LLM支持的格式,具体方法如下所示:
# chatglm-6b weight convert
huggingface_glm_convert \
-in_file /workspace/chatglm-6b \
-saved_dir /workspace/chatglm-6b-converted \
-infer_gpu_num 1 \
-weight_data_type fp16 \
-model_name chatglm-6b
Chatglm2-6b、Chatglm3-6b模型
通过huggingface_chatglm2_convert脚本将huggingface格式的Chatglm2-6b、Chatglm3-6b模型转换为DeepGPU_LLM支持的格式,以Chatglm2-6b模型为例,具体方法如下所示:
# chatglm2-6b weight convert
huggingface_chatglm2_convert \
-in_file /workspace/chatglm2-6b \
-saved_dir /workspace/chatglm2-6b-converted \
-infer_gpu_num 1 \
-weight_data_type fp16 \
-model_name chatglm2-6b
Baichuan 1/2系列模型
通过huggingface_baichuan_convert脚本将huggingface格式的Baichuan 1/2系列模型转换为DeepGPU_LLM支持的格式,具体方法如下所示:
# baichuan-13b weight convert
huggingface_baichuan_convert \
-in_file /workspace/Baichuan-13B-Chat \
-saved_dir /workspace/Baichuan-13B-Chat-converted \
-infer_gpu_num 2 \
-weight_data_type fp16 \
-model_name baichuan-13b
通义千问Qwen系列模型
通过huggingface_qwen_convert脚本将huggingface格式的通义千问Qwen系列模型转换为DeepGPU_LLM支持的格式,具体方法如下所示:
#qwen-7b weight convert
huggingface_qwen_convert \
-in_file /workspace/Qwen-7B-Chat \
-saved_dir /workspace/Qwen-7B-Chat-converted \
-infer_gpu_num 1 \
-weight_data_type fp16 \
-model_name qwen-7b
modelscope格式的模型
下载modelscope格式的开源模型。
modelscpoe是阿里达摩院提供的开源模型平台,下载modelscope格式的模型有如下两种方式。本步骤以通义千问Qwen模型为例。
进行modelscope格式的开源模型格式转换。
步骤二:参考推理示例代码
进行大模型推理任务时,需要您自行准备模型的推理代码,您可以参考本步骤提供的四类模型的推理示例代码。
LIama系列模型推理参考代码
import time
from deepgpu_llm.llama_model import llama_model
from deepgpu_llm.deepgpu_utils import DeepGPUGenerationConfig
from transformers import LlamaTokenizer
model_path = '/workspace/llama-7b-hf-converted'
tokenizer = LlamaTokenizer.from_pretrained(model_path)
model_path = "/workspace/llama-7b-hf-converted/1-gpu"
tensor_para_size = 1
precision = 0 # fp16 mode
kv_cache_quant_level = 1
generation_config = DeepGPUGeneration Config(max_new_tokens=128)
model = llama_model(model_path, tensor_para_size,
precision, kv_cache_quant_level,
generation_config=generation_config)
payload = ["Hey, are you consciours? Can you talk to me?"]
start_ids = tokenizer(payload, return_tensors="pt").input_ids
for i in range(5):
s = time.time()
output = model.generate(start_ids, generation_config)
e = time.time()
print("---- time", e - s)
tokens = output[0].tolist()
for i in range(len(tokens)):
print(tokenizer.decode(tokens[i][0]))
ChatGLM系列模型推理参考代码
import time
from deepgpu_llm.chatglm_model import chatglm_model
from deepgpu_llm.deepgpu_utils import DeepGPUGenerationConfig
from transformers import AutoTokenizer
model_path = "/workspace/chatglm2-6b-converted"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model_path = "/workspace/chatglm2-6b-converted/1-gpu"
tp_size = 1
precision = 0 # fp16 mode
generation_config = DeepGPUGenerationConfig(max_new_tokens=128)
model = chatglm_model(model_path, tp_size, precision,
generation_config=generation_config)
payload = ["Hey, are you consciours? Can you talk to me?"]
start_ids = tokenizer(payload, return_tensors="pt").input_ids
for i in range(8):
start = time.time()
output = model.generate(start_ids, generation_config)
end = time.time()
print("-----", end - start)
tokens = output.tolist()
for i in range(len(tokens)):
print(tokenizer.decode(tokens[i][0]))
Baichuan系列模型推理参考代码
import time
from deepgpu_llm.baichuan_model import baichuan_model
from deepgpu_llm.deepgpu_utils import DeepGPUGenerationConfig
from transformers import AutoTokenizer
model_path = "/path/to/Baichuan-13B-Chat-converted"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model_path = "/path/to/Baichuan-13B-Chatconverted/2-gpu"
tp_size = 2 # tensor parallel
precision = 0 # fp16 mode
kv_cache_quant_level = 0
generation_config = DeepGPUGenerationConfig(max_new_tokens=128)
model = baichuan_model(model_path, tp_size, precision, kv_cache_quant_level,
generation_config=generation_config)
payload = "你好!你是谁?"
start_ids = tokenizer(payload, return_tensors="pt").input_ids
for i in range(8):
start = time.time()
output = model.generate([start_ids], generation_config)
end = time.time()
print("-----", end - start)
tokens = output[0].tolist()
print(tokenizer.decode(tokens[0][0], skip_special_tokens=True))
通义千问Qwen系列模型推理参考代码
import time
from deepgpu_llm.qwen_model import qwen_model
from deepgpu_llm.deepgpu_utils import DeepGPUGenerationConfig
from transformers import AutoTokenizer
model_path = "/path/to/Qwen-7B-Chat-converted"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model_path = "/path/to/Qwen-7B-Chat-converted/1-gpu"
tp_size = 1 # tensor parallel
precision = 0 # fp16 mode
kv_cache_quant_level = 0
generation_config = DeepGPUGenerationConfig(max_new_tokens=128)
model = qwen_model(model_path, tp_size, precision, kv_cache_quant_level,
generation_config=generation_config)
payload = "你好!你是谁?"
start_ids = tokenizer(payload, return_tensors="pt").input_ids
for i in range(8):
start = time.time()
output = model.generate([start_ids], generation_config)
end = time.time()
print("-----", end - start)
tokens = output[0].tolist()
print(tokenizer.decode(tokens[0][0], skip_special_tokens=True))
(可选)步骤三:使用API接口推理
如果需要通过DeepGPU-LLM的API接口方式来使用DeepGPU-LLM进行推理服务,请参考本步骤操作,以Llama模型和ChatGLM模型为例。
使用DeepGPU-LLM进行推理的相关代码总览如下:

导入deepgpu_llm模块。
以Llama模型和ChatGLM模型为例:
Llama模型
# llama model
from deepgpu_llm.llama_model import llama_model
from deepgpu_llm.deepgpu_utils import DeepGPUGenerationConfig
from transformers import LlamaForCausalLM, LlamaTokenizer
ChatGLM模型
# chatglm model
from deepgpu_llm.llama_model import chatglm_model
from deepgpu_llm.deepgpu_utils import DeepGPUGenerationConfig
from transformers import AutoModel, AutoTokenizer
创建tokenizer和model参数并配置generation_config。
generation_config在模型创建或推理时配置,配置完成后即成为模型的一个属性。如果再次调用模型的相关函数,则无需再配置generation_config。
以Llama模型和ChatGLM模型为例:
Llama模型
model_path = '/workspace/llama-7b-hf-converted'
tokenizer = LlamaTokenizer.from_pretrained(model_path)
model_path = "/workspace/llama-7b-hf-converted/1-gpu"
tensor_para_size = 1
precision = 0 # fp16 mode
kv_cache_quant_level = 0
model = llama_model(model_path, tensor_para_size, precision,
kv_cache_quant_level, generation_config=generation_config)
ChatGLM模型
model_path = "/workspace/chatglm2-6b-converted"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model_path = "/workspace/chatglm2-6b-converted/1-gpu"
tp_size = 1
precision = 0 # fp16 mode
generation_config = DeepGPUGenerationConfig(max_new_tokens=512, top_k=1)
model = chatglm_model(model_path, tp_size,
precision, generation_config=generation_config)
llama_model()和chatglm_model()使用的主要参数说明如下:
参数名称 | 说明 |
model_dir
| 指定模型转换后的存放路径。 |
tensor_para_size
| 模型推理使用的GPU卡数。 |
precision
| 推理精度。取值范围: |
kv_cache_quant_level(ChatGLM模型暂不支持)
| 量化级别参数。取值范围 0:无量化压缩。 1:K8_V8量化。 2:K8_V4量化。 3:K4_V4量化。
默认值:0。
说明 推荐使用等级1,模型能在几乎不损失精度的情况下提升批量大小,并在批量大小较大时会显著提升推理速度。 |
generation_config
| 即DeepGPUGenerationConfig,用于配置生成相关参数。如果在此处配置该参数,则forward或者generate函数可以不用再配置。 |
如果管理生成参数的generation_config为DeepGPUGenerationConfig类时,其代码原型如下:
class DeepGPUGenerationConfig():
def __init__(self, **kwargs):
self.max_new_tokens = kwargs.pop("max_new_tokens", 512)
self.do_sample = kwargs.pop("do_sample", None)
self.num_beams = kwargs.pop("num_beams", None)
self.temperature = kwargs.pop("temperature", None)
self.top_k = kwargs.pop("top_k", None)
self.top_p = kwargs.pop("top_p", None)
self.repetition_penalty = kwargs.pop("repetition_penalty", None)
self.presence_penalty = kwargs.pop("presence_penalty", None)
self.len_penalty = kwargs.pop("len_penalty", None)
self.beam_search_diversity_rate = kwargs.pop("beam_search_diversity_rate", None)
如果您没有设置DeepGPUGenerationConfig中的数据成员(即为None),则DeepGPU-LLM将读取原模型文件中的生成配置文件config.ini(如果配置文件存在),如果没有配置文件,则将使用默认配置参数。具体说明如下:
参数名 | 类型 | 说明 |
max_new_tokens
| int | 指定模型的最大生成长度。 |
do_sample
| bool | 是否开启sample模式。如果开启,则DeepGPU_LLM将为不同batch生成不同结果。 |
num_beams
| int | beam search的束宽度。 |
temperature
| float | 取值区间:[0.0, 1.0]。该值越大则生成文本多样性越大。 |
top_k
| int | 取值区间为大于0的整数。代表生成时从概率最大的top_k个值中选择。 |
top_p
| float | 取值区间:[0.0, 1.0]。只从概率之和超过top_p的最小单词集合中进行采样,而不考虑其他低概率的单词。 |
repetition_penalty
| float | 取值区间:[0.0, 1.0]。连续重复词惩罚,越大代表出现重复词的概率越大。 |
presence_penalty
| float | 取值区间:[0.0,1.0]。当该参数设置较高时,生成模型会尽量避免产生重复的词语、短语或句子。 |
len_penalty
| float | 该值大于0时鼓励模型生成更长的序列,小于0时鼓励模型生成更短的序列。 |
beam_search_diversity_rate
| float | beam search使用到的参数。 |
生成token list作为模型推理输入参数。
payload = ["Hey, are you consciours? Can you talk to me?"]
start_ids = tokenizer(payload, return_tensors="pt").input_ids
调用推理接口model.generate()。
output = model.generate([start_ids],generation_config)
主要参数说明如下:
输入参数 | 说明 |
start_ids
| 输入步骤3已生成的token list。 |
generation_config
| DeepGPUGenerationConfig类,用于调整生成参数。 |
打印输出结果。
tokens = output[0].tolist()
for i in range(len(tokens)):
print(tokenizer.decode(tokens[i][0]))
(可选)步骤四:参考对话接口示例
如果需要通过对话接口方式来使用DeepGPU-LLM进行推理服务,请参考对话接口chat和流式对话接口Stream Chat示例。
对话接口chat示例
model.chat()是一个简单的对话接口,调用即可打印回复语句。其示例代码如下:
import torch
from deepgpu_llm.baichuan_model import baichuan_model
from deepgpu_llm.deepgpu_utils import DeepGPUGenerationConfig
from transformers import AutoTokenizer
model_path = "path/to/your/llama_tokenizer"
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model_path = "path/to/your/llama_converted/1-gpu"
tp_size = 1
generation_config = DeepGPUGenerationConfig(max_new_tokens=256)
model = baichuan_model(model_path, tp_size, generation_config=generation_config)
query = "Hello!"
response = model.chat(tokenizer, query, response_skip_inputs=False)
query = "What is your name ?"
response = model.chat(tokenizer, query, stream=True, response_skip_inputs=True)
主要参数说明如下:
参数 | 说明 |
tokenizer
| 创建的Tokenizer对象。 |
input_string
| 输入字符串。 |
stream
| 决定是否使用流式输出打印结果,默认值:False。 |
generation_config
| DeepGPUGenerationConfig,默认值:None。 |
response_skip_inputs
| 打印的输出中是否包含输入字符串,默认值:False。 |
流式对话接口Stream Chat示例
stream chat功能仅支持beam width=1的情况,但可以进行多batch的流式输出。其示例代码如下:
import time
from deepgpu_llm.llama_model import llama_model
from deepgpu_llm.deepgpu_utils import DeepGPUGenerationConfig,DeepGPUStreamer
from transformers import AutoModel, LlamaTokenizer
#仅支持beam_width=1的情况
#读取模型
model_path = "/root/workspace/Llama-2-7b-chat-hf-converted"
tokenizer = LlamaTokenizer.from_pretrained(model_path, trust_remote_code=True)
streamer = DeepGPUStreamer(tokenizer)
generation_config = DeepGPUGenerationConfig(max_new_tokens = 512,
**{'skip_special_tokens' : True})
model_path = "/root/workspace/Llama-2-7b-chat-hf-converted/1-gpu"
tp_size = 1
model = llama_model(model_path, tp_size, generation_config = generation_config)
if __name__ == '__main__' :
#初始化输入
query = 'china is a large country.'
inputs = []
inputs.append(tokenizer(query, return_tensors='pt').input_ids)
#内存预热
t1 = time.time()
for output in model.stream_generate(input_ids=inputs,generation_config):
printable_str = streamer.handel_str(output[0][0][0])
print(printable_str, flush=True, end="")
print(streamer.end())
print("-----------------test now ----------------------")
t1 = time.time()
#调用stream_generete方法,逐个token返回结果
for output in model.stream_generate(input_ids=inputs,skip_inputs=True):
#处理输出token,设置回车、空格、判断是否是单词前缀等,使字符串可打印出来
printable_str = streamer.handel_str(output[0][0][0])
#打印
print(printable_str, flush=True, end="")
#清除DeepGPUStreamer中的字符串缓存
print(streamer.end())
t2 = time.time()
print("cost time:",t2-t1)
stream_generate接口说明如下:
for output in model.stream_generate(input_ids=inputs,generation_config=generation_config,skip_inputs=True)
说明 返回值output是一个[batch_size , 1 , seq_len]的tensor。
参数名 | 说明 |
input_ids
| 输入token list |
generation_config
| DeepGPUGenerationConfig类,用于调整生成参数 |
skip_inputs
| 输出句子中是否打印输入query。 |
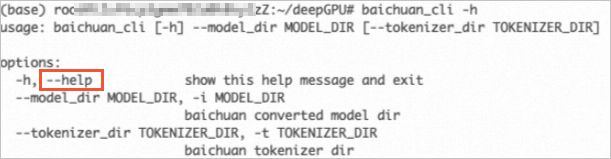
步骤五:运行推理代码
除了您自行准备模型推理代码外,DeepGPU-LLM安装包也为您提供了几个模型的运行实例,您可以通过自带的可运行代码实例体验模型运行效果和了解具体代码细节。具体运行命令可以通过--help来查看具体的配置选项。例如:
本步骤以DeepGPU-LLM提供的四类模型的流式输出对话实例代码为例,进行模型推理服务的调用命令如下:
Llama模型流式输出对话实例
DeepGPU-LLM提供了Llama模型的流式对话实例代码:llama_cli,该实例支持llama系列和llama2系列模型推理,调用命令如下:
llama_cli -i models/deepgpu/llama2-7b/1-gpu/ -t models/llama2-7b/
Baichuan模型流式输出对话实例
DeepGPU-LLM提供了Baichuan模型的流式对话实例代码:baichuan_cli,该实例支持baichuan 1/2系列模型推理,调用命令如下:
baichuan_cli -i models/deepgpu/baichuan2-7b-chat/1-gpu/ -t models/Baichuan2-7B-Chat/
调用完成后,您可以输入内容和Baichuan模型进行对话。例如:

ChatGLM模型流式输出对话实例
DeepGPU-LLM提供了ChatGLM模型的流式对话实例代码:chatglm_cli,该实例支持chatglm-6b和chatglm2-6b等模型推理,调用命令如下:
chatglm_cli -i models/deepgpu/chatglm2-6b/1-gpu/ -t models/chatglm2-6b/
调用完成后,您可以输入内容和ChatGLM模型进行对话。例如:

通义千问Qwen模型流式输出对话实例
DeepGPU-LLM提供了Qwen模型的流式对话实例代码:qwen_cli,该实例支持qwen-7b和qwen-14b等模型推理,调用命令如下:
qwen_cli -i models/deepgpu/qwen-7b-chat/1-gpu/ -t models/Qwen-7B-Chat/
调用完成后,您可以输入内容和ChatGLM模型进行对话。例如:

联系我们
如果您在安装和使用DeepGPU-LLM过程中遇到问题,欢迎加入钉钉群23210030587寻求帮助(钉钉通讯客户端下载地址)。